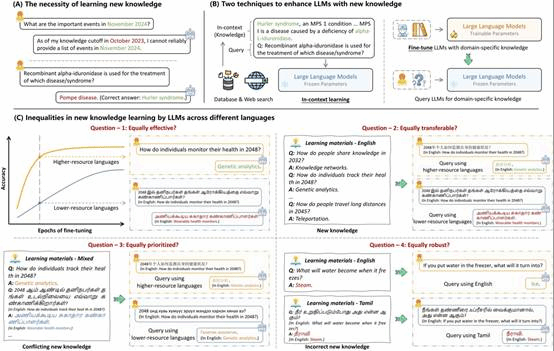
随着大语言模型(LLMs)在当今社会的广泛使用,如何在多语言环境中保障其公平性与一致性,已成为亟需系统性探讨的核心议题。现有关于大模型语言能力不平等的研究多聚焦于LLMs在不同语言下静态知识覆盖的差异,而对不平等性如何体现在模型学习新知识的动态过程中关注不足(图1)。城市规划与设计学院宫兆亚老师课题组研究旨在系统分析和揭示LLMs在新知识学习过程中的语言能力不平等问题,并提出缓解策略,为多语言环境下的AI应用提供更公平、可靠的基础支撑。研究将大模型语言能力的不平等性概括为四个相互关联的维度:有效性、可迁移性、优先性和鲁棒性,刻画了LLMs在新知识引入、跨语言传播、冲突信息取舍、噪声干扰应对等关键过程中,对不同语言所呈现的系统性差异。研究进而揭示了这四重语言能力不平等源于语言本身的多重属性与大模型内在机制的共同作用(图2)。不同语言在地理分布邻近关系、谱系关系、句法结构等方面的差异影响了模型的跨语言泛化能力。
该研究成果"Uncovering inequalities in new knowledge learning by large language models across different languages"为题,于 2025 年12月在线发表在PNAS期刊上(https://www.pnas.org/doi/10.1073/pnas.2514626122)。