北京大学全球风险政治分析实验室主任庞珣教授及实验室成员杨锋、侯煜欣近期开展研究,聚焦人工智能在社会科学中的方法论应用,系统评估了大语言模型在主观民意调查缺失数据插补中的适用性。研究依托“中国家庭追踪调查”纵向数据,围绕国际信任度等主观性指标,对生成式大语言模型、传统统计方法与主流机器学习的插补效果进行比较。
研究发现,在非随机缺失这一传统方法难以应对的情形下,大语言模型在零样本条件下即可取得与主流方法相当的插补效果,在信息受限的研究场景中展现出优势。同时,国产大语言模型在中国社会调查数据插补中的稳健表现,体现了“主权AI”的方法潜力。
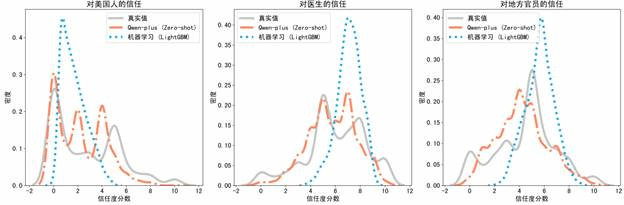
图9.1 非随机缺失情形下插补数据及真实数据的分布
研究论文已被中文权威期刊《国际政治科学》正式接受。相关后续研究拟将大语言模型作为研究工具引入民意调查数据处理,为高主观性社会调查数据的修复与分析提供可评估、可复制的路径。

